Most applications read data far more often than they write it. A product catalog page might serve ten thousand reads for every single write. Yet we build one model to handle both, and then wonder why performance tuning feels like a zero-sum game between read speed and write correctness.
CQRS – Command Query Responsibility Segregation – says: stop compromising. Build separate models for reading and writing data. It’s a deceptively simple idea that, applied at the wrong time, creates more problems than it solves. Applied at the right time, it unlocks performance and clarity that a single model can’t achieve.
What CQRS Actually Is
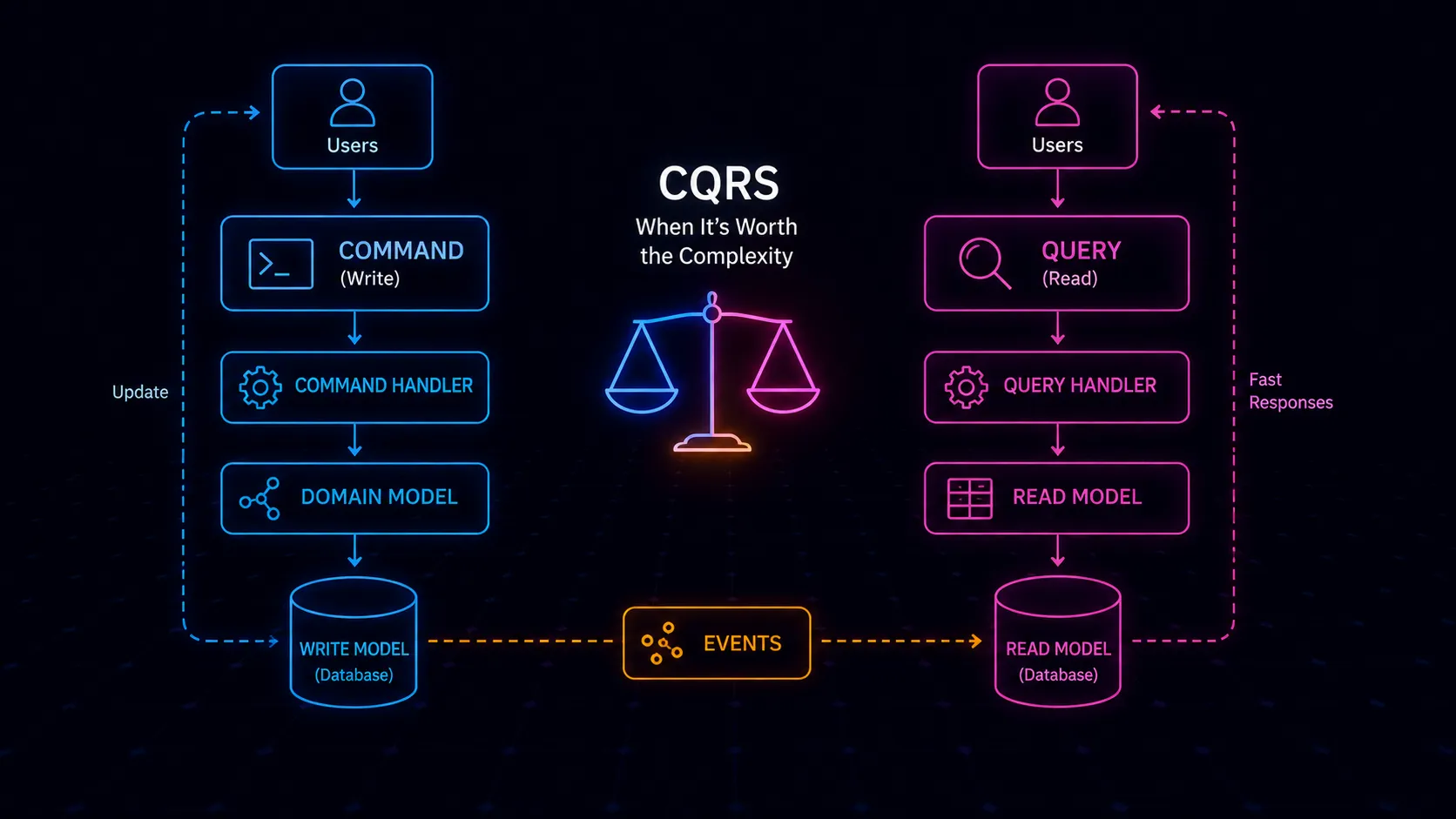
At its core, CQRS splits your application into two sides. The command side handles writes: creating, updating, deleting data with full validation, business rules, and consistency guarantees. The query side handles reads: serving data in whatever shape the consumer needs, optimized for speed and convenience.
This goes beyond having separate API endpoints for reads and writes. The models themselves differ. The write model might be a normalized relational schema enforcing referential integrity and domain invariants. The read model might be a set of denormalized views, pre-computed projections, or an entirely different data store optimized for the specific queries your application needs.
The key insight is that read and write concerns pull data models in opposite directions. Writes want normalization, constraints, and transactional integrity. Reads want flat, pre-joined, fast-to-query structures. A single model serving both is a compromise, and sometimes that compromise costs more than maintaining two models.
A Concrete Example
Consider an e-commerce product catalog. The write side needs to enforce business rules: prices must be positive, SKUs unique, inventory counts accurate, category assignments valid. A normalized relational model works well here – products, categories, pricing tiers, and inventory as separate tables with foreign keys and constraints.
But the read side has different needs entirely. A product listing page wants a denormalized view with the product name, primary image URL, current price, average rating, and stock status – all in one object, no joins. A search results page wants something similar but weighted by relevance. A product detail page needs reviews, related products, and pricing history, all pre-assembled.
Building these read patterns from the normalized write model means complex joins on every request, or caching layers that introduce their own staleness and invalidation problems. With CQRS, the read side maintains its own denormalized structures, purpose-built for each query pattern. Writes update the normalized model; read models get updated asynchronously.
The difference is tangible. A product listing query against the write model might join five tables and take 50ms under load. The same data from a read-optimized projection is a single-table lookup returning in under 5ms. Multiply that across thousands of concurrent users browsing the catalog, and the performance gap becomes a business problem.
The Simple Version: Start Here
Full CQRS with separate databases and event buses isn’t where you should begin. The simple version uses the same database but different models for reading and writing.
Materialized views. Your database maintains pre-computed views based on your normalized tables. Reads query the views; writes update the base tables. PostgreSQL materialized views, for instance, can be refreshed on a schedule or trigger.
Read-optimized tables. Maintain denormalized tables alongside your normalized schema. When a write occurs, update both the normalized tables and the denormalized read tables within the same transaction. No eventual consistency, no synchronization lag. The cost is write amplification – every write does more work – but for read-heavy workloads, this trade-off is overwhelmingly favorable.
Separate query models in code. Even without database-level changes, you can separate your read and write models in application code. Write operations go through a rich domain model with validation and business rules. Read operations use lightweight DTOs and optimized queries that bypass the domain model entirely.
This version gives you the architectural clarity of CQRS – separate concerns, optimized models – without the operational complexity of distributed systems. For most teams, this is the right stopping point. You get 80% of the benefit with 20% of the complexity.
One underappreciated advantage: since both models share a database, you can update them in the same transaction. No eventual consistency to worry about, no synchronization lag, no event infrastructure. The read model is always current. When someone tells you CQRS requires eventual consistency, they’re confusing the pattern with one specific implementation of it.
The Full Version: Separate Data Stores
When the simple version isn’t enough – when read and write scaling needs diverge significantly, or when different storage technologies would serve each side better – you move to separate data stores.
The write side might use PostgreSQL for its transactional guarantees. The read side might use Elasticsearch for full-text search, Redis for low-latency lookups, or a document store like MongoDB for flexible, denormalized views. Each store is optimized for its specific access pattern.
Synchronization between the two sides happens through events. When a write occurs, an event is published. Read-side handlers consume these events and update their data stores accordingly.
This introduces eventual consistency. After a write completes, there’s a window – milliseconds to seconds, usually – where the read side hasn’t caught up. For many applications, this is perfectly acceptable. Users don’t typically refresh a page within milliseconds of submitting a change. For others, it’s a dealbreaker.
The infrastructure cost is real: message brokers, event handlers, monitoring for synchronization lag, dead letter queues for failed events, and strategies for rebuilding read models when they drift or when you change their schema. This isn’t free, and it’s not simple.
Handling Read-Your-Own-Writes
The most common user experience problem with eventually consistent CQRS is the “I just saved this, where did it go?” scenario. A user submits a form, the page reloads, and their change isn’t visible yet because the read model hasn’t caught up.
Several mitigation strategies exist. Route the user’s next read to the write database directly after they perform a write – this requires session awareness in your routing layer. Include a version token with the write response and have the read side wait for that version before responding. Or design the UI to show the submitted data optimistically while the read model catches up in the background.
None of these are free, but they’re well-understood patterns. The important thing is to decide on your consistency strategy before building the system, not after users start filing support tickets about missing data.
CQRS and Event Sourcing: Related but Separate
CQRS and event sourcing show up together so often that people assume they’re a package deal. They’re not.
Event sourcing stores state as a sequence of events rather than current values. Instead of a products table with a row showing the current price, you store ProductCreated, PriceChanged, InventoryUpdated events and derive current state from the event log.
CQRS pairs well with event sourcing because the event log provides a natural mechanism for projecting read models: replay events into whatever denormalized shape you need. But CQRS works perfectly well without event sourcing, using traditional state-based storage on the write side and projecting read models through other synchronization mechanisms.
Don’t adopt event sourcing just because you’re doing CQRS. Event sourcing solves specific problems – audit trails, temporal queries, the ability to replay history into new projections. If you don’t need those capabilities, traditional state storage on the write side is simpler and better understood.
The combination of CQRS and event sourcing is powerful but compounds complexity. You’re now maintaining separate read and write models, an event store, projection logic, and snapshot strategies for performance. That’s a significant investment in infrastructure and expertise. Adopt each pattern on its own merits, not as an assumed pair.
What You Gain
Independent scaling. Read and write workloads can scale separately. If your application handles a hundred reads per write, you can scale the read infrastructure without touching the write side. This matters when read and write traffic patterns differ significantly.
Optimized data models. Each side uses the best model for its job. Writes get normalized, constrained schemas. Reads get denormalized, pre-computed views. No compromises, no impedance mismatch.
Clearer separation of concerns. Commands and queries are inherently different operations with different requirements. Separating them in code makes each side simpler to reason about. Write-side code focuses on business rules and validation. Read-side code focuses on assembling and serving data efficiently.
Flexibility in technology choices. The read side can use a completely different technology than the write side. Relational database for writes, search engine for reads, cache for hot data – each chosen for what it does best.
Simpler read-side code. Without CQRS, read endpoints often contain defensive logic to assemble data from a model designed for writes. With a dedicated read model, queries become straightforward lookups against purpose-built structures. Less code, fewer bugs, faster development of new read endpoints.
What It Costs
Eventual consistency is hard to reason about. When can a user expect to see their changes? What happens when they don’t? How do you handle read-your-own-writes semantics? These questions don’t have universal answers, and getting them wrong creates confusing user experiences.
Data synchronization has failure modes. Events can be lost, duplicated, or arrive out of order. Read models can drift from the write model. Detecting and recovering from synchronization failures requires monitoring, alerting, and sometimes manual intervention.
More infrastructure to operate. Separate databases, message brokers, event handlers – each is a component that can fail, needs monitoring, and requires expertise to operate. Your on-call burden increases.
Debugging across the split is harder. A bug might be in the write side, the event publishing, the event handling, or the read model projection. Tracing a problem across this pipeline takes more tooling and more skill than debugging a single-model application.
Team cognitive load. Everyone working on the system needs to understand the split, the synchronization model, and the consistency guarantees. New team members have a steeper learning curve. Simple features that would be one database write in a CRUD application now require updating command handlers, events, and read model projections.
Testing surface area grows. You need to test the write model, the read model, and the synchronization between them. Integration tests become more important and more complex. A write that succeeds but produces a broken read projection is a category of bug that doesn’t exist in single-model systems.
Schema evolution gets harder. Changing the write model means updating events, event handlers, and read model projections. Changing a read model means replaying or migrating existing projections. In a single-model system, you change the schema and update the queries. In CQRS, changes ripple through multiple components.
When CQRS Is Worth It
CQRS earns its complexity in specific situations:
High read/write ratio disparity. When reads outnumber writes by orders of magnitude and read performance is critical, the ability to optimize and scale the read side independently is genuinely valuable. Think content platforms, product catalogs, dashboards.
Complex domain models. When the write side involves rich business logic – multi-step validation, aggregate consistency, complex state machines – separating it from read concerns keeps the domain model clean. The domain model handles invariants; read models handle presentation.
Different scaling requirements. When read traffic spikes independently of write traffic (a flash sale hitting your product catalog, a report going viral), separate scaling avoids write-side impact. You can spin up additional read replicas or cache nodes without worrying about write-side contention.
Collaborative or multi-tenant systems. When multiple users or tenants are writing to overlapping data while many more are reading it, separating the two paths reduces contention and makes it easier to implement tenant-specific read optimizations.
Event-driven architecture already in place. If you’re already publishing domain events for other reasons, projecting read models from those events is a natural extension rather than new infrastructure.
Multiple read consumers with different needs. When a mobile app, a web frontend, an admin dashboard, and a reporting system all need the same underlying data in different shapes, CQRS lets each consumer have its own optimized read model rather than forcing a single API to serve all of them poorly.
When to Skip It
Be honest about whether you actually need CQRS:
Simple CRUD applications. If your application is mostly forms that write data and pages that display it, CQRS adds ceremony without benefit. A well-indexed database with an ORM handles this fine.
Small teams. CQRS increases the surface area of every feature. If your team is small enough that everyone already understands the whole system, the separation adds coordination cost without clarity benefit.
When one model works. If your read and write patterns don’t meaningfully conflict – if the same normalized schema serves both well enough – CQRS solves a problem you don’t have.
When eventual consistency is unacceptable. Financial systems, inventory management, anything where users must see the immediate result of their action – full CQRS with separate data stores introduces consistency challenges that may not be worth solving.
When you’re not feeling pain. This is the most important signal. CQRS is a response to specific problems: read performance bottlenecks, write model complexity bleeding into read paths, scaling limitations. If you’re not experiencing these problems, you’re adding complexity speculatively.
Early-stage products. Startups and new products change constantly. The read patterns you optimize for today won’t be the ones you need in six months. CQRS makes pivoting harder because you’re maintaining two models instead of one. Get product-market fit first, then optimize the architecture.
The Bottom Line
CQRS is a powerful pattern applied too early by most teams that adopt it. The architecture conference talks make it sound like the natural evolution of any serious system. It isn’t. Greg Young, who coined the term, has said repeatedly that CQRS should be applied to specific bounded contexts, not entire systems.
In practice, most applications are better served by a single well-designed data model with good indexes, a caching layer, and read replicas if read scaling is needed. These are boring solutions. They’re also well-understood, easy to operate, and sufficient for the vast majority of workloads.
Start with the simple version – separate read and write models in code, same database. That alone provides meaningful architectural clarity without operational complexity. Move to separate data stores only when you have measurable evidence that the simple version isn’t enough.
The teams that benefit most from full CQRS are the ones who tried simpler approaches first and hit real limits. They understand their read/write patterns, they know where the bottlenecks are, and they’re adding complexity to solve a specific, documented problem.
If you’re considering CQRS, ask yourself: can I point to a specific, measured problem that CQRS solves and simpler approaches don’t? If the answer is yes, proceed deliberately, starting with the simple version. If the answer is “not yet, but we might need it someday” – that’s a no. Build the simpler thing. You can always add CQRS to a bounded context later when the pain is real. You can’t easily remove it once it’s woven into your architecture.