EC2 Auto Scaling and AWS Lambda both solve the problem of handling variable traffic—but they operate on fundamentally different assumptions about what “variable” means. Picking the wrong one doesn’t break your application, but it will either cost more than necessary or introduce latency and cold start problems that erode user experience. For a broader look at the serverless vs. traditional server trade-offs, see the AWS Lambda vs EC2 comparison.
How Each Handles Scale
EC2 Auto Scaling adds or removes EC2 instances in response to metrics—typically CPU utilization, request count, or a custom CloudWatch metric. Scaling out takes 2–5 minutes: AWS has to boot a new instance, run your user data script, and pass health checks before traffic routes to it. Scaling in is equally slow. The model assumes traffic changes gradually enough that this lag doesn’t matter.
AWS Lambda scales in milliseconds. Each invocation is isolated—AWS spins up execution environments in parallel, up to your account’s concurrency limit (default 1,000, raisable). There’s no provisioning delay for the first request, only a cold start penalty (typically 100–500ms for JVM/Python runtimes, under 50ms for Go/Node) when a new execution environment initializes.
The core difference: Auto Scaling manages capacity, Lambda manages execution environments. One thinks in instances, the other thinks in function calls.
The Cost Model Is Completely Different
EC2 Auto Scaling cost = (instance hours) × (instance price). If you’re running 3 × m5.large instances during peak and 1 during off-peak, you’re paying for all of it—even idle capacity. Auto Scaling can reduce waste, but instances that pass health checks are billing.
Lambda cost = (invocations × duration × memory). If nobody calls your function, you pay nothing. At high volume, Lambda gets expensive quickly: 1 billion 100ms requests at 512MB costs roughly $1,667/month at standard pricing—more than a fleet of EC2 instances handling the same throughput.
The crossover point varies by workload, but most teams find Lambda becomes cost-inefficient above ~10M invocations/month for anything CPU-intensive. Conversely, EC2 Auto Scaling rarely makes sense for workloads averaging fewer than a few requests per second.
Latency Characteristics
EC2 Auto Scaling doesn’t add latency to individual requests—traffic hits a running instance immediately. The latency cost is in the scaling event itself: if a traffic spike arrives before new instances are healthy, you absorb it on existing capacity (or drop requests if at saturation).
Lambda adds per-invocation latency via cold starts. This is manageable with Provisioned Concurrency (which pre-warms execution environments at a fixed cost), but that partially defeats Lambda’s cost model for predictable traffic. For APIs where p99 latency matters, cold starts are a real consideration.
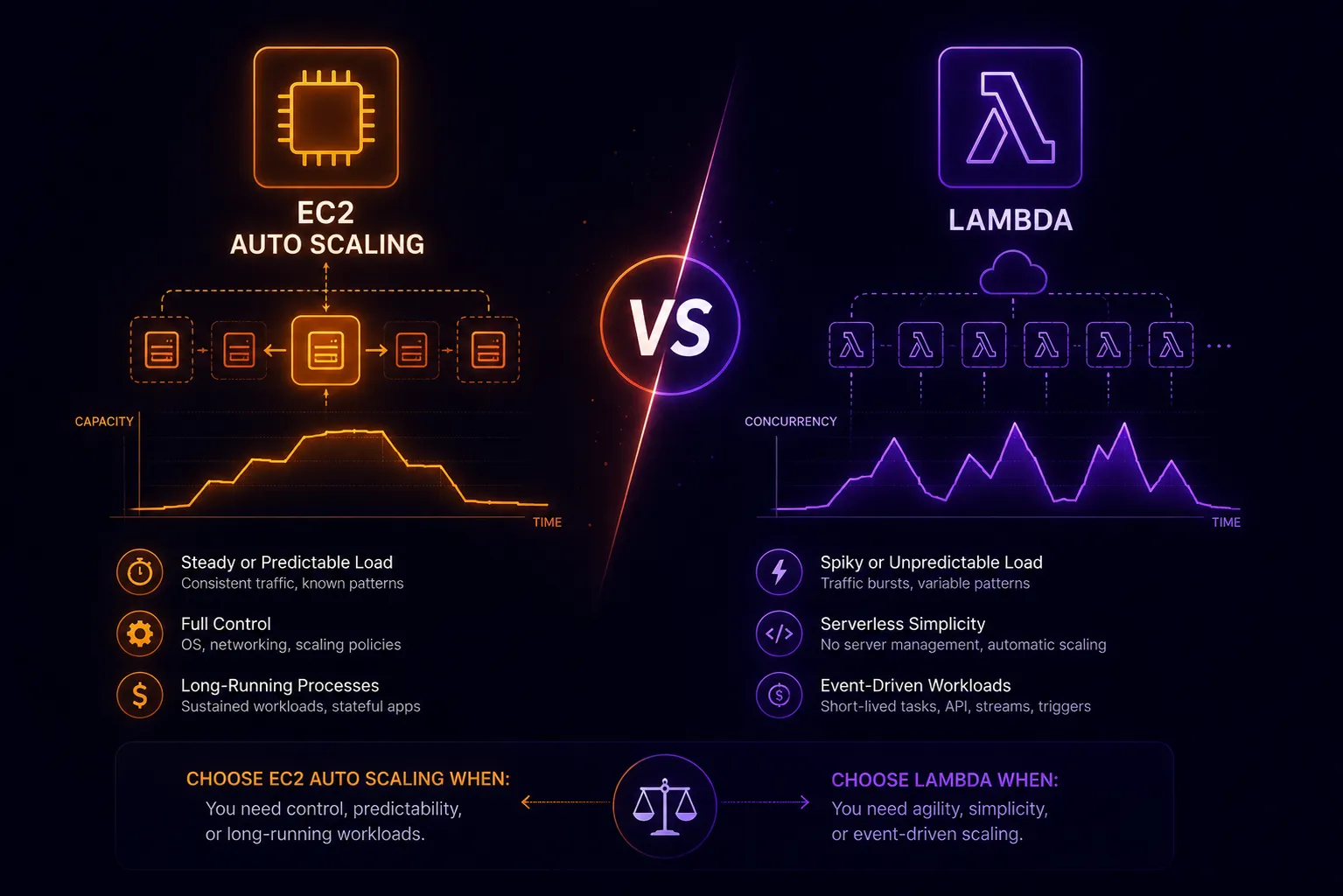
When EC2 Auto Scaling Wins
Long-running workloads. Lambda has a 15-minute execution limit. Batch jobs, video processing, or anything that runs longer than that can’t use Lambda directly.
Steady, predictable traffic. If your traffic curve is smooth and doesn’t spike more than 2× in under a minute, Auto Scaling handles it efficiently. The per-minute billing of EC2 (with reserved instances or savings plans) often beats Lambda at sustained load.
Stateful applications. Lambda is stateless by design. Applications that maintain in-memory state, open database connections aggressively, or rely on local disk between requests are difficult to port to Lambda without architectural changes. EC2 just runs your existing application.
High CPU/memory workloads. Lambda maxes out at 10GB memory and 6 vCPUs. A compute-intensive workload that needs a c6i.8xlarge can’t run on Lambda.
GPU workloads. Lambda has no GPU option. ML inference, video encoding, and scientific computing stay on EC2.
When Lambda Wins
Unpredictable spikes. If traffic goes from 0 to 10,000 requests in 30 seconds (triggered by a marketing email, a viral moment, or a cron job kicking off), Lambda handles it without any capacity planning. EC2 Auto Scaling would still be booting instances when the spike is over.
Infrequent invocations. A webhook handler that fires 500 times per day, a nightly data export, a Slack bot that responds to commands—these pay essentially nothing on Lambda and would require a constantly-running EC2 instance (even a t3.micro) otherwise.
Event-driven architectures. Lambda integrates natively with SQS, SNS, S3, DynamoDB Streams, Kinesis, and API Gateway. The wiring is minimal compared to polling these services from an EC2 instance.
Short, parallel tasks. Resizing 10,000 images, validating 50,000 records, or fan-out processing are natural fits for Lambda’s parallel execution model. EC2 Auto Scaling can do this too, but requires more orchestration.
The Hybrid Pattern
Many production systems use both:
- Lambda for API endpoints, async event processing, and anything with spiky, infrequent traffic
- EC2 Auto Scaling for long-running workers, compute-heavy batch jobs, and high-throughput services where per-invocation Lambda costs add up
If your workload outgrows both and needs containers, the ECS vs EKS comparison covers the next set of trade-offs.
This isn’t over-engineering—it’s matching the compute model to the access pattern. An application that serves user-facing API requests (Lambda) while running nightly ML batch processing (EC2) is using the right tool for each problem.
The Decision Framework
Choose Lambda when:
- Traffic is unpredictable or bursty
- Invocations are infrequent (under ~10M/month for typical workloads)
- Execution time is under 15 minutes
- You want zero infrastructure management
- The workload is event-driven
Choose EC2 Auto Scaling when:
- Traffic is sustained and predictable
- The workload runs longer than 15 minutes
- You need GPU, high memory, or specialized instance types
- The application is stateful or has in-process dependencies
- Volume is high enough that per-invocation Lambda pricing exceeds instance cost
The question isn’t “which is better”—it’s “which model fits this workload’s traffic shape and execution characteristics.”