Traditional ACID transactions assume a single database. You begin a transaction, do your work, and either commit or roll back. Clean, reliable, understood for decades. Then microservices happened, and suddenly your “place an order” operation spans four services with four databases. Two-phase commit technically exists for this scenario, but it requires all participants to hold locks until everyone agrees to commit. In practice, it kills throughput, creates tight coupling, and doesn’t tolerate network partitions well. It doesn’t scale.
The saga pattern is the alternative that actually works in distributed systems.
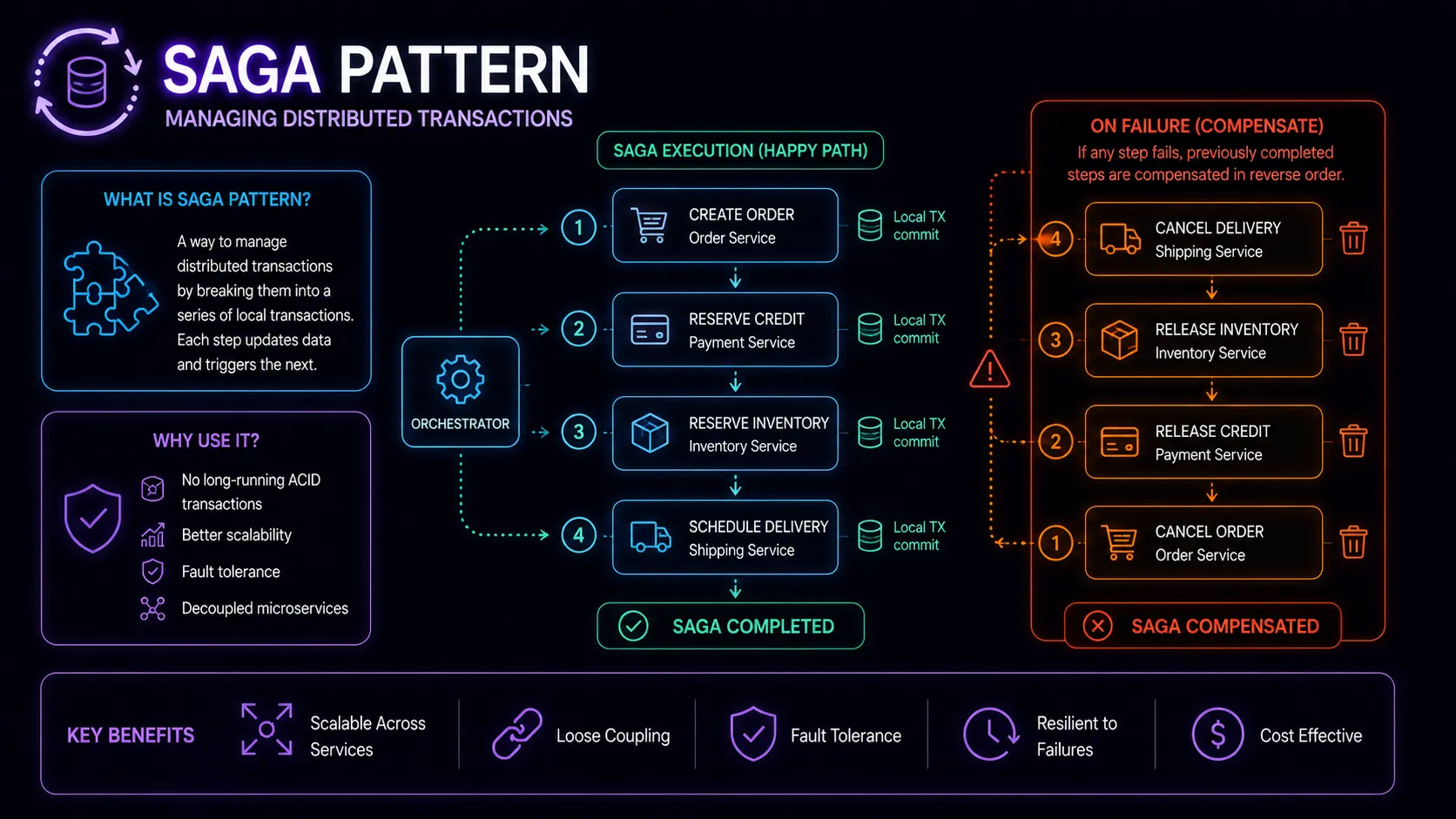
What a Saga Is
A saga is a sequence of local transactions. Each service performs its own transaction and publishes an event or notifies the next step. If any step fails, previously completed steps execute compensating transactions to undo their effects.
The key insight: instead of one atomic transaction across services, you get a series of smaller transactions with a defined rollback path. You trade strict ACID guarantees for availability and loose coupling. What you get in return is a system that can handle partial failures gracefully without distributed locks.
A saga guarantees that either all steps complete successfully, or all completed steps are compensated. It doesn’t give you isolation—other operations can see intermediate states. That’s a real trade-off, and you need to design around it.
A Concrete Example
Consider an e-commerce order flow involving four services:
- Order Service — creates the order record (status: PENDING)
- Inventory Service — reserves the requested items
- Payment Service — charges the customer’s payment method
- Shipping Service — initiates fulfillment
The happy path is straightforward. Each step succeeds, the order moves to CONFIRMED, and the customer gets their package. But what happens when step 3 fails—the customer’s card is declined?
Compensating sequence:
- Payment failed — no compensation needed (it never succeeded)
- Inventory Service receives a compensating request — releases the reserved items
- Order Service receives a compensating request — sets order status to CANCELLED
Each compensating action is the logical inverse of its corresponding forward action. “Reserve inventory” compensates with “release inventory.” “Create order” compensates with “cancel order.”
This is manageable with four services. Now consider that real-world sagas can span six, eight, or more services. The compensating logic grows with each step, and the failure modes multiply.
Choreography vs Orchestration
There are two fundamental approaches to coordinating saga steps. The choice shapes your entire architecture.
Choreography
In choreography, there’s no central coordinator. Each service listens for events and reacts by performing its local transaction, then emitting its own event. The RabbitMQ vs Kafka choice often drives which event infrastructure underpins choreography-based sagas. The order service creates an order and emits OrderCreated. The inventory service hears that event, reserves stock, and emits InventoryReserved. The payment service hears that, charges the card, and emits PaymentProcessed.
For compensation, the same pattern runs in reverse. PaymentFailed triggers the inventory service to release stock, which emits InventoryReleased, which triggers the order service to cancel the order.
The workflow is implicit—it exists in the collective behavior of the services, not written down in any single place.
Orchestration
In orchestration, a dedicated saga orchestrator tells each service what to do and when. The orchestrator holds the saga’s state machine: which steps have completed, which step is next, and what compensations to run if something fails.
The orchestrator calls the inventory service directly: “Reserve these items for order #1234.” When it gets a success response, it calls the payment service: “Charge $50 to card ending 4242.” If payment fails, the orchestrator knows exactly which compensations to execute and in what order.
The workflow is explicit—you can read the orchestrator’s code and understand the entire flow.
Choreography Deep Dive
Choreography appeals to teams that value loose coupling. Services don’t know about each other. They publish events and subscribe to events. Adding a new step to the saga means deploying a new service that listens for the right event—no existing services change.
Where it works well:
- Simple sagas with three or four steps
- Teams that already have mature event infrastructure
- Workflows where services genuinely don’t need to know about each other
- Organizations where independent team ownership of services matters most
Where it breaks down:
- Debugging is painful. When an order gets stuck in a weird state, tracing the flow means correlating events across multiple services, message brokers, and log stores. There’s no single place to ask “what happened to saga #5678?”
- Implicit workflows drift. Over time, nobody remembers the complete flow. New engineers add event listeners without fully understanding the downstream effects. The saga’s behavior becomes emergent rather than designed.
- Event storms. A single failure can cascade into a flood of compensating events. If services aren’t idempotent, reprocessed events cause duplicate actions.
- Circular dependencies. Service A reacts to events from Service B, which reacts to events from Service A. These cycles are hard to detect and harder to debug.
Choreography is the natural choice for teams already committed to event-driven architecture. But most teams underestimate how much observability tooling they’ll need to make it manageable.
Orchestration Deep Dive
Orchestration puts control in one place. The orchestrator is a service whose sole job is managing the saga lifecycle. It knows every step, every compensation, and every possible state transition.
Where it works well:
- Complex sagas with many steps or conditional branching
- Workflows where you need clear visibility into saga state
- Teams that want centralized error handling and retry logic
- Systems where business stakeholders need to understand the flow
Where it causes problems:
- Orchestrator complexity. The orchestrator accumulates logic from every saga it manages. It can become a god service that knows too much about too many domains.
- Coupling to the orchestrator. Every service in the saga depends on being called by the orchestrator. Changing the saga means changing the orchestrator, redeploying it, and hoping nothing else breaks.
- Single point of failure. If the orchestrator goes down, all in-flight sagas stall. You need the orchestrator to be highly available, which means distributed state management for the orchestrator itself.
- Temptation to over-orchestrate. Once you have an orchestrator, everything starts looking like it needs orchestration. Simple request-response flows get shoehorned into sagas unnecessarily.
For most teams building their first saga implementation, orchestration is the safer choice. The explicit state machine is easier to reason about, test, and debug than emergent choreographed behavior.
Compensating Transactions Are Not Simple Undos
This is where most saga tutorials wave their hands. “Just undo the previous step” sounds simple until you think about it for five minutes.
Irreversible actions. Your saga sends a confirmation email after payment succeeds. Payment later gets reversed due to fraud detection. You can’t unsend the email. The compensation here isn’t “undo” but “mitigate”—send a cancellation email, flag the account, trigger a review.
External system interactions. You called a third-party shipping API to create a label. The compensation isn’t “delete the label” because the API might not support that. You might need to void the shipment, which has different semantics and might cost money.
Time-dependent state. Releasing reserved inventory sounds simple, but what if another saga already allocated that inventory to a different order during the window between reservation and compensation? Your compensation logic needs to handle contention.
Semantic compensation. Sometimes the compensation isn’t reversing the action but recording that it was logically reversed. A “refund” isn’t the absence of a charge—it’s a new transaction that offsets the original. Your data model needs to support this.
Design compensations as first-class operations with their own validation, error handling, and idempotency guarantees. They’re not afterthoughts.
Common Pitfalls
Lack of idempotency. Network retries, duplicate messages, and at-least-once delivery guarantees mean your saga steps will execute more than once. If “reserve inventory” isn’t idempotent, you’ll double-reserve. Every saga step and every compensation must produce the same result whether executed once or five times. Use idempotency keys tied to the saga ID.
Ignoring intermediate states. Between step 2 completing and step 3 starting, the system is in a partially committed state. Other operations can see an order with reserved inventory but no payment. If your UI or other services can’t handle these intermediate states, users see confusing behavior.
No saga state persistence. If the orchestrator (or the choreographed flow) crashes mid-saga, you need to resume from where it left off. That requires persisting saga state to a durable store after each step. In-memory saga state is a time bomb.
Poor observability. When a saga fails at step 5 of 7, you need to know: which steps completed, which compensations ran, which compensations succeeded, and what the current state is. Without distributed tracing and saga-specific dashboards, debugging saga failures is miserable. Correlate all saga steps under a single saga ID and make that ID searchable across every service.
Compensations that fail. What happens when the compensation itself fails? You need a strategy—retry with backoff, dead-letter queue for manual intervention, or an escalation path. Compensations failing silently leaves the system in an inconsistent state that nobody notices until a customer complains.
When to Use the Saga Pattern
Sagas make sense when you have genuine cross-service business processes that can’t be collapsed into a single service. Specific indicators:
- Multiple services own different parts of a business operation. Order placement touches orders, inventory, payments, and fulfillment—each owned by a different team with a different database.
- Long-running workflows. The operation takes minutes, hours, or days to complete. Holding a distributed lock for that duration is impractical.
- Failure recovery matters. The business requires that partial failures are handled gracefully rather than leaving orphaned state scattered across services.
- You’ve already committed to microservices. Sagas are a consequence of distributed data ownership. If you’ve split your data across services, you need a pattern like sagas to maintain consistency.
When Not to Use It
You can use a single database transaction. If the services involved share a database (or can reasonably share one), a regular transaction is simpler and stronger. Don’t introduce saga complexity for a problem a BEGIN/COMMIT solves.
The workflow is simple request-response. If service A calls service B and that’s the whole operation, you don’t need a saga. A synchronous call with error handling is fine. Sagas are for multi-step operations with rollback requirements.
You’re using microservices but don’t need to be. Sometimes the right answer is consolidating services so the transaction stays local. Sagas are a tool for managing distributed complexity, not a justification for creating it.
Your team isn’t ready for the operational overhead. Sagas require solid observability, idempotent services, reliable messaging, and mature incident response. If you’re still figuring out basic service-to-service communication, sagas will compound your problems.
The Bottom Line
The saga pattern is the realistic answer to distributed transactions. It acknowledges that you can’t have ACID across service boundaries and gives you a structured way to handle the complexity that follows.
Orchestration is the pragmatic starting point for most teams—explicit state machines are easier to build, test, and debug than implicit choreographed flows. Move to choreography when you outgrow the orchestrator or when your organization’s service ownership model demands it.
The hard part isn’t choosing choreography or orchestration. It’s designing compensations that actually work, making every step idempotent, and building enough observability to debug failures at 2 AM. Get those three things right and the saga pattern will serve you well. Get them wrong and you’ll have a distributed system that fails in ways nobody can explain.