Services / Reliability & Observability
Reliability and observability for teams that need signal, not blind spots.
From noisy alerts to actionable insights — build systems that are visible, resilient, and easy to operate with monitoring, alerting, tracing, and metrics that surface what matters.

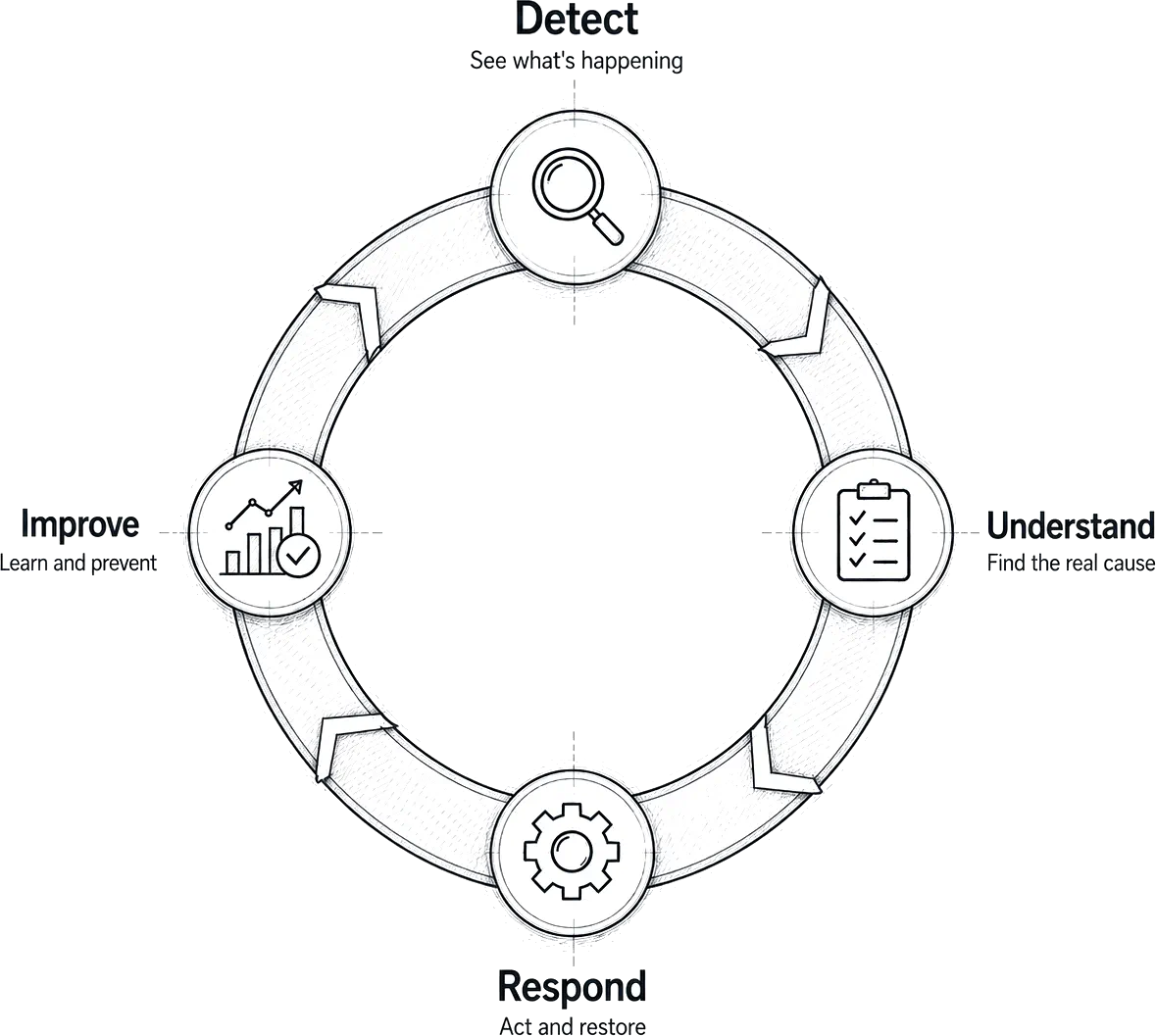
The reliability loop
Observability pillars
Metrics
Understand system health over time.
Logs
Investigate with rich context.
Traces
Follow requests end-to-end.
Dashboards
Clarity for every level of the team.
Outcomes that matter
See clearly. Respond quickly. Build with confidence.
50%
faster MTTR
Detect and resolve incidents before they spread.
70%+
alert noise reduction
Tune signals so on-call sees what matters.
99.9%
reliability target
Instrumentation and process that hold up in production.